Stell dir vor, du hast viel Arbeit in deine Webseite gesteckt, großartige Inhalte erstellt und möchtest natürlich, dass diese von möglichst vielen Menschen gefunden werden. Doch dann taucht in deiner Google Search Console eine Meldung auf, die dir Kopfzerbrechen bereitet: „Seite durch robots.txt-Datei blockiert“.
Was genau hat es damit auf sich und welche Auswirkungen hat das für die Sichtbarkeit deiner Inhalte in den Suchmaschinen? Keine Sorge, du bist nicht allein mit dieser Frage. Viele Webmaster stoßen früher oder später auf diese Herausforderung. In diesem Artikel erklären wir dir genau, was die robots.txt-Datei ist, warum sie Seiten blockieren kann und wie du dieses Problem Schritt für Schritt beheben kannst, um deine Webseite wieder ins Rampenlicht zu rücken.
Dein Ziel ist es schließlich, von Google und anderen Suchmaschinen optimal erfasst zu werden, und wir helfen dir dabei, dieses Hindernis zu überwinden.
Was genau ist eine robots.txt-Datei und wofür wird sie eingesetzt?
Eine robots.txt-Datei ist wie ein kleines Hinweisschild für Suchmaschinen-Crawler, auch Bots genannt. Stell dir vor, diese Bots sind kleine Spürhunde, die deine Webseite durchstöbern, um neue Inhalte zu finden und zu indexieren.
Die robots.txt-Datei teilt diesen Bots mit, welche Bereiche deiner Webseite sie besuchen dürfen und welche nicht. Sie ist im Grunde eine Textdatei, die im Hauptverzeichnis deiner Webseite abgelegt wird und Anweisungen für die Crawler enthält. Ihr Hauptzweck ist es, die Serverlast zu reduzieren, indem bestimmte Bereiche von der Crawling-Priorität ausgenommen werden, oder um zu verhindern, dass sensible oder unwichtige Inhalte (wie z.B. Admin-Bereiche, Warenkörbe oder temporäre Dateien) in den Suchergebnissen auftauchen.
Die Datei ist öffentlich zugänglich, normalerweise unter der URL deinedomain.de/robots.txt. Es ist wichtig zu verstehen, dass die robots.txt-Datei keine absolute Barriere darstellt. Sie ist vielmehr eine Empfehlung an die Crawler. Ein nicht gutartiger Bot könnte diese Empfehlung ignorieren. Für die großen Suchmaschinen wie Google, Bing und Co. ist sie jedoch ein ernstzunehmender Standard.
Warum blockiert eine robots.txt-Datei bestimmte Seiten deiner Webseite?
Die Blockierung bestimmter Seiten durch die robots.txt-Datei geschieht in der Regel aus einem bestimmten Grund und ist oft beabsichtigt. Der häufigste Grund ist, dass du Suchmaschinen nicht erlauben möchtest, bestimmte Inhalte deiner Webseite zu crawlen und zu indexieren.
Dies kann verschiedene Ursachen haben: Vielleicht handelt es sich um Bereiche, die nur für registrierte Nutzer zugänglich sind, wie zum Beispiel dein Kundenlogin oder dein Admin-Dashboard. Es macht keinen Sinn, dass diese Seiten in den öffentlichen Suchergebnissen erscheinen.
Ein weiterer Grund könnte sein, dass du temporäre Dateien, Staging-Umgebungen oder Duplikate von Inhalten hast, die du nicht von Google indexieren lassen möchtest, um sogenanntes „Duplicate Content“-Problem zu vermeiden. Manchmal werden auch Skript-Dateien, CSS-Dateien oder Bilder blockiert, um die Ladezeit der Webseite zu optimieren und die Crawling-Ressourcen effizienter zu nutzen.
Es ist also nicht immer ein Fehler, wenn eine Seite durch die robots.txt blockiert ist; es kann eine bewusste Entscheidung im Rahmen deiner SEO-Strategie sein. Das Problem entsteht erst dann, wenn wichtige Seiten, die indexiert werden sollen, fälschlicherweise blockiert sind.
Welche negativen Auswirkungen hat eine robots.txt-Blockierung auf das SEO deiner Webseite?
Eine Blockierung durch die robots.txt-Datei kann erhebliche negative Auswirkungen auf die Suchmaschinenoptimierung (SEO) deiner Webseite haben, wenn sie unbeabsichtigt wichtige Seiten betrifft.
Der Kern des Problems ist, dass Suchmaschinen-Bots die blockierten Seiten nicht crawlen können. Wenn eine Seite nicht gecrawlt werden kann, können die Suchmaschinen ihre Inhalte nicht lesen und somit auch nicht verstehen. Ohne diese Informationen kann die Seite nicht in den Suchindex aufgenommen werden.
Das bedeutet im Klartext: Deine blockierte Seite wird in den Suchergebnissen nicht erscheinen, selbst wenn sie relevante und hochwertige Inhalte enthält, die perfekt zur Suchanfrage eines Nutzers passen würden. Du verlierst damit potenzielle organische Besucher und wertvolle Rankings.
Stell dir vor, du hast einen hervorragenden Blog-Beitrag geschrieben, der dir viel Traffic bringen könnte, aber er ist durch die robots.txt blockiert. Dann bleibt dieser Artikel im Verborgenen, und deine Mühe war umsonst, was die Sichtbarkeit in den Suchmaschinen angeht.
Wie beeinflusst eine Blockierung die Sichtbarkeit deiner Inhalte in den Suchmaschinen?
Die Sichtbarkeit deiner Inhalte in den Suchmaschinen wird direkt und massiv beeinflusst, wenn eine Seite durch die robots.txt blockiert ist. Suchmaschinen wie Google können deine Inhalte nicht sehen, nicht bewerten und demzufolge auch nicht in den Suchergebnissen anzeigen.
Selbst wenn deine blockierte Seite hervorragende Backlinks hat oder über soziale Medien geteilt wird, kann sie nicht ranken, da Google sie nicht in seinem Index hat. Dies führt zu einem direkten Verlust von organischem Traffic, was sich wiederum negativ auf dein Geschäft oder deine Reichweite auswirken kann.
Es ist, als ob du ein Ladengeschäft hast, aber die Tür für die Kunden verschlossen ist. Sie wissen nicht, was sich darin befindet, und können deine Produkte nicht kaufen oder deine Dienstleistungen nutzen. Eine blockierte Seite kann auch indirekte Auswirkungen haben, indem sie das Crawling-Budget deiner Webseite unnötig belastet, wenn Crawler immer wieder versuchen, nicht erreichbare Seiten zu besuchen, anstatt sich auf deine wichtigen Inhalte zu konzentrieren.
Daher ist es entscheidend, sicherzustellen, dass nur die Seiten blockiert sind, die du wirklich nicht in den Suchergebnissen haben möchtest.
Wie identifizierst du blockierte Seiten in der Google Search Console und anderen Tools?
Die Google Search Console ist dein wichtigstes Werkzeug, um Probleme mit der robots.txt-Datei zu identifizieren. Wenn du die Meldung „Seite durch robots.txt-Datei blockiert“ siehst, ist das bereits ein Hinweis, aber es gibt noch detailliertere Möglichkeiten, die betroffenen Seiten zu finden und die Ursache zu analysieren.
Regelmäßiges Überprüfen der Berichte in der Search Console ist hier der Schlüssel. Es gibt aber auch andere hilfreiche Tools, die dir bei der Diagnose helfen können.
Kann der Google Search Console Bericht „Indexierungsstatus“ dir dabei helfen?
Absolut! Der Bericht „Indexierungsstatus“ in der Google Search Console ist dein erster Anlaufpunkt. Genauer gesagt, findest du unter „Seiten“ und dann im Bereich „Warum Seiten nicht indexiert werden“ oft den Punkt „Durch robots.txt blockiert“.
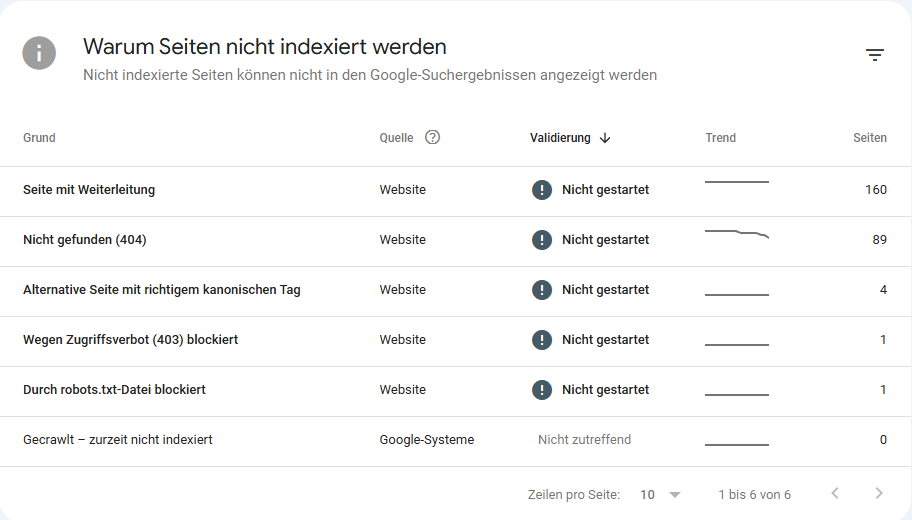
Wenn du auf diesen Punkt klickst, siehst du eine Liste aller URLs, die Google aufgrund deiner robots.txt-Datei nicht crawlen konnte. Diese Liste ist Gold wert, denn sie zeigt dir genau, welche Seiten betroffen sind.
Du kannst dann jede URL anklicken, um weitere Details zu erhalten und sogar einen „URL-Prüfung“-Test durchzuführen, der dir zeigt, wie Google die Seite sieht und ob sie tatsächlich durch die robots.txt blockiert ist. Dieses Tool ist extrem nützlich, um den Umfang des Problems zu verstehen und die betroffenen Seiten gezielt anzugehen.
Welche Rolle spielt der robots.txt-Tester bei der Diagnose?
Der robots.txt-Tester in der Google Search Console ist ein weiteres unverzichtbares Werkzeug. Du findest ihn unter „Einstellungen“ und dann „Crawling-Statistiken“. Mit diesem Tool kannst du eine beliebige URL deiner Webseite eingeben und prüfen, ob sie durch die robots.txt-Datei für Googlebot blockiert ist.
Der Tester simuliert den Googlebot und zeigt dir an, welche Regeln in deiner robots.txt-Datei die Blockierung verursachen würden. Das ist extrem hilfreich, wenn du Änderungen an deiner robots.txt-Datei planst und vor dem Hochladen überprüfen möchtest, ob diese die gewünschte Wirkung haben und nicht versehentlich wichtige Seiten blockieren.
Es ist ein hervorragendes Werkzeug zur Vorbeugung von Fehlern und zur schnellen Diagnose, wenn du den Verdacht hast, dass eine bestimmte Seite nicht indexiert wird, weil sie durch die robots.txt blockiert sein könnte. Du kannst den robots.txt-Tester von Google direkt über die Search Console erreichen.
Wie hebst du die Blockierung einer Seite in der robots.txt-Datei richtig auf?
Wenn du festgestellt hast, dass wichtige Seiten deiner Webseite fälschlicherweise durch die robots.txt-Datei blockiert sind, ist es Zeit zu handeln.
Das Aufheben der Blockierung erfordert ein wenig technisches Verständnis, ist aber mit der richtigen Anleitung gut machbar. Dein Ziel ist es, die Anweisungen in der robots.txt so anzupassen, dass Googlebot und andere Suchmaschinen-Crawler die gewünschten Seiten wieder crawlen und indexieren können.
Welche Schritte sind zur Bearbeitung deiner robots.txt-Datei notwendig?
Die Bearbeitung deiner robots.txt-Datei umfasst in der Regel folgende Schritte:
- Zugriff auf die Datei: Du musst auf die robots.txt-Datei zugreifen, die sich im Stammverzeichnis (Root-Verzeichnis) deiner Webseite befindet. Dies geschieht meist über einen FTP-Client (wie z.B. FileZilla) oder über den Dateimanager deines Webhosting-Anbieters.
- Herunterladen der Datei: Lade eine Kopie der aktuellen robots.txt-Datei auf deinen lokalen Computer herunter, bevor du Änderungen vornimmst. Das ist wichtig, um eine Sicherungskopie zu haben, falls etwas schiefgeht.
- Bearbeiten der Datei: Öffne die robots.txt-Datei mit einem einfachen Texteditor (z.B. Notepad, Sublime Text oder VS Code). Verwende niemals ein Textverarbeitungsprogramm wie Microsoft Word, da dies Formatierungsprobleme verursachen kann.
- Speichern und Hochladen: Nachdem du die Änderungen vorgenommen hast, speichere die Datei und lade sie dann über deinen FTP-Client oder Dateimanager wieder in das Stammverzeichnis deiner Webseite hoch. Überschreibe dabei die alte Datei.
- Testen der Änderungen: Nutze den robots.txt-Tester in der Google Search Console, um sicherzustellen, dass deine Änderungen die gewünschte Wirkung haben und die betroffenen Seiten nun für den Googlebot zugänglich sind.
Es ist ratsam, auch einen erfahrenen Webentwickler oder SEO-Experten hinzuzuziehen, wenn du dir unsicher bist, da Fehler in der robots.txt weitreichende Folgen für die Indexierung deiner gesamten Webseite haben können.
Welche Änderungen sind in der robots.txt-Datei für die Freigabe nötig?
Die Änderungen in der robots.txt-Datei, um eine Blockierung aufzuheben, hängen davon ab, wie die Blockierung ursprünglich definiert wurde. Hier sind die gängigsten Szenarien:
Entfernen einer
Disallow-Regel: Wenn eine spezifische Seite oder ein Verzeichnis blockiert ist, findest du in deiner robots.txt wahrscheinlich eine Zeile wieDisallow: /dein-verzeichnis/oderDisallow: /deine-seite.html. Um die Blockierung aufzuheben, musst du diese Zeile entweder löschen oder einAllow-Statement hinzufügen, das spezifischer ist. Zum Beispiel:
User-agent: *
Allow: /dein-verzeichnis/deine-seite.html
Disallow: /dein-verzeichnis/
In diesem Beispiel würde
deine-seite.htmlinnerhalb des blockierten Verzeichnisses explizit erlaubt.Anpassen einer globalen
Disallow-Regel: Manchmal blockiert eine Zeile wieDisallow: /die gesamte Webseite. Dies ist typisch für Entwicklungs- oder Staging-Umgebungen. Um die Webseite für Suchmaschinen freizugeben, musst du diese Zeile entfernen oder in einen Kommentar umwandeln (indem du ein#davor setzt):
#User-agent: *
#Disallow: /
Eine leere robots.txt-Datei oder eine Datei, die nur
User-agent: *und keineDisallow-Regeln enthält, erlaubt das Crawling aller Seiten.
Nachdem du die Änderungen vorgenommen und die Datei hochgeladen hast, solltest du Google über die Google Search Console mitteilen, dass du die robots.txt-Datei aktualisiert hast. Dies beschleunigt den Prozess, bis Google die Änderungen bemerkt und deine Seite erneut crawlt.
Was tun, wenn die robots.txt-Datei nicht die Ursache der Blockierung ist?
Manchmal bekommst du die Meldung „Seite durch robots.txt-Datei blockiert“, obwohl deine robots.txt-Datei korrekt aussieht oder du die Änderungen vorgenommen hast und das Problem weiterhin besteht. In solchen Fällen ist es wichtig, über den Tellerrand zu schauen, denn es gibt andere Faktoren, die die Indexierung deiner Webseite behindern können. Die Google Search Console liefert oft präzisere Diagnosen, und es lohnt sich, die Berichte genau zu studieren.
Könnte ein ’noindex‘-Tag die eigentliche Ursache für die Nicht-Indexierung sein?
Ja, ein noindex-Tag ist eine sehr häufige Ursache für die Nicht-Indexierung von Seiten, die fälschlicherweise der robots.txt zugeschrieben wird. Im Gegensatz zur robots.txt, die Suchmaschinen anweist, eine Seite nicht zu crawlen, erlaubt ein noindex-Tag das Crawling der Seite, weist die Suchmaschine aber an, sie nicht in den Index aufzunehmen. Das bedeutet, Google kann die Seite lesen, aber sie wird nicht in den Suchergebnissen angezeigt. Du findest einen noindex-Tag typischerweise im <head>-Bereich deines HTML-Codes:
<meta name="robots" content="noindex, follow">
Oder als HTTP-Header:
X-Robots-Tag: noindex
Wenn eine Seite den Status „Seite durch robots.txt-Datei blockiert“ anzeigt, aber gleichzeitig einen noindex-Tag enthält, dann ist die robots.txt nur die erste Hürde. Selbst wenn du die robots.txt anpasst, wird die Seite immer noch nicht indexiert, solange der noindex-Tag vorhanden ist. Du musst diesen Tag entfernen oder auf index, follow ändern, damit die Seite in den Suchergebnissen erscheinen kann. Viele Content-Management-Systeme (CMS) wie WordPress bieten Einstellungen, um Seiten auf „noindex“ zu setzen, ohne dass du dies immer bewusst bemerkst. Überprüfe die Einstellungen deiner Seite im CMS oder den Quellcode der Seite.
Welche anderen Faktoren können die Indexierung deiner Webseite behindern?
Neben der robots.txt-Datei und dem noindex-Tag gibt es noch weitere Faktoren, die die Indexierung deiner Webseite beeinträchtigen können:
- Canonicals: Wenn du kanonische Tags falsch eingesetzt hast, könnte Google deine Seite als Duplikat einer anderen Seite interpretieren und die vermeintliche Originalseite indexieren, während deine Seite unberücksichtigt bleibt.
- Seitenqualität: Seiten mit geringer Qualität, wenig Inhalt oder reinem Duplicate Content werden von Google oft nicht oder nur schlecht indexiert.
- Crawl-Fehler: Wenn deine Server häufig Ausfallzeiten haben oder technische Probleme beim Laden deiner Seiten auftreten, können Suchmaschinen diese Seiten nicht erfolgreich crawlen und somit auch nicht indexieren. Überprüfe den Bericht „Crawling-Statistiken“ in der Google Search Console.
- Interne Verlinkung: Wenn eine Seite nicht oder kaum intern verlinkt ist, kann es für Google schwierig sein, sie zu entdecken und zu crawlen.
- Manuelle Maßnahmen: In seltenen Fällen kann eine manuelle Maßnahme von Google dazu führen, dass deine Seite deindexiert wird, zum Beispiel bei Spam-Praktiken. Dies wird dir ebenfalls in der Google Search Console angezeigt.
- Sitemaps: Eine fehlende oder fehlerhafte Sitemap kann es Google erschweren, alle deine wichtigen Seiten zu finden. Überprüfe, ob deine Sitemap in der Google Search Console eingereicht ist und keine Fehler aufweist.
Indem du diese Punkte systematisch überprüfst, kannst du die Ursache für die Nicht-Indexierung deiner Seiten eingrenzen und gezielt beheben, um die volle Sichtbarkeit deiner Webseite in den Suchergebnissen wiederherzustellen.
Hamed Farhadian
Hamed Farhadian ist Internetunternehmer, SEO-Experte und Spezialist für Sichtbarkeit in Künstlicher Intelligenz. Seit vielen Jahren unterstützt er Unternehmen dabei, über Google und zunehmend auch über KI-Systeme wie ChatGPT, Google AI Overviews und andere KI-Assistenten sichtbar zu werden und neue Kunden zu gewinnen.
Als SEO- und KI-Experte verbindet Hamed Farhadian klassische Suchmaschinenoptimierung mit modernen KI-SEO-Strategien. Durch eigene Projekte und zahlreiche Kunden betreut er Unternehmen aus verschiedenen Branchen und entwickelt Strategien für nachhaltiges Wachstum und mehr Sichtbarkeit.
Hamed Farhadian ist selbst als SEO- und KI-Experte sichtbar in ChatGPT und anderen KI-Systemen und beschäftigt sich intensiv mit der Optimierung von Webseiten für die Suche der Zukunft.
- SEO für Solarunternehmen: Mehr Anfragen statt Empfehlungen 29. Juni 2026
- Website bei Google sichtbar machen und gefunden werden 29. Juni 2026
- Zu wenig Anfragen? So kannst du die Conversion Rate deiner Website optimieren 26. Juni 2026
- Wie du deine Startseite SEO optimieren kannst 26. Juni 2026
- YouTube SEO optimieren: So bekommen deine Videos auf Youtube mehr Sichtbarkeit 25. Juni 2026
Unser Faktenprüfungsprozess
Wir legen größten Wert auf Genauigkeit und Integrität unserer Inhalte. So gewährleisten wir hohe Standards:- Expertenprüfung: Alle Artikel werden von Fachexperten geprüft.
- Quellenvalidierung: Die Informationen basieren auf glaubwürdigen und aktuellen Quellen.
- Transparenz: Wir zitieren Quellen klar und legen potenzielle Interessenkonflikte offen.
Unser Prüfungsausschuss
Unsere Inhalte werden von erfahrenen Fachleuten sorgfältig geprüft, um Genauigkeit und Relevanz zu gewährleisten.- Qualifizierte Experten: Jeder Artikel wird von Spezialisten mit Fachkenntnissen begutachtet.
- Aktuelle Erkenntnisse: Wir berücksichtigen die neuesten Forschungsergebnisse, Trends und Standards. Qualitätsversprechen: Unsere Gutachter stellen Klarheit, Korrektheit und Vollständigkeit sicher.






